Appeals Court Says Google’s Book-Scanning Project Is Legal Fair Use
While Google Books search results do show actual pages of scanned books, they also omit pages believed to be irrelevant to the search terms.
The Google Library Project is more than a decade old and involves partnerships with a number of top research libraries. These institutions select books from their collections for Google to scan and make searchable. This was done without permission of the authors involved.
Since the project launched in 2004, Google has scanned more than 20 million titles, though most of them are out of print books, many of which are already in the public domain.
In addition to the Library Project, there is Google Books, which allows users to freely search for terms and phrases — just like a normal Google search, but one that turns up results from scanned books instead of websites.
While Google does sometimes include links of where books can be purchased, the company says it doesn’t make any money from those links. Furthermore, it does not — unlike its web search engine — run ads against Google Books search results.
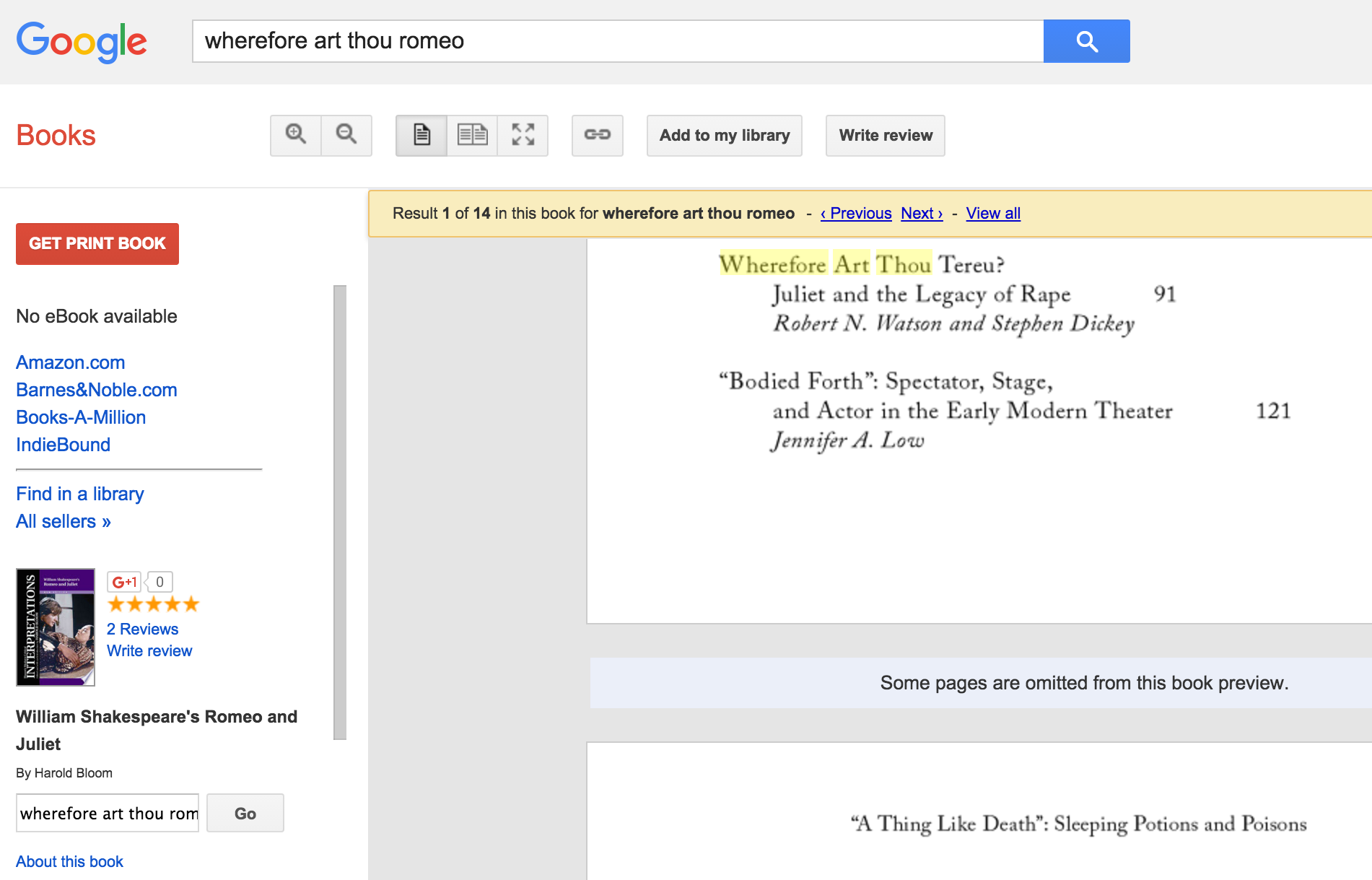
The search results may pull up what Google describes as “snippets” — actual images from the scanned books — but which some critics believe cross the line into copyright violation, especially because it often brings in pages before and after the sought-after term.
For example, a search for “wherefore art thou romeo” on Google Books may lead you to Harold Bloom’s analysis of Romeo & Juliet.
The results don’t turn up the full book, but because of the frequency of the use of the name “Romeo” in the book, much of this particular title is freely available to peruse. However, as in all Books titles, there are certain sections that are “blacklisted” and will not show up.
Google has made certain copyright-centered concessions over the years. In 2005, it began letting authors request removal of snippets from Books search results. Additionally, if a single snippet is deemed acceptable to meet the needs of a search — say a dictionary or glossary entry — no neighboring pages are shown.
Libraries that provide books to Google for scanning are allowed to download a digital copy of the scanned pages, but are contractually required to abide by copyright law and not disseminate that file to the public at large.
In Sept. 2005, Authors Guild — a professional organization representing thousands of professional writers — sued Google on behalf of its affected members.
Three years later, Google and the Guild reached a settlement that would have seen the search engine pay out around $125 million to copyright holders but which would also allow the company to continue scanning titles and make money from them by running ads against the results.
This settlement was ultimately rejected by the court in 2011 because it would give Google a “significant advantage over competitors, rewarding it for engaging in wholesale copying of copyrighted works without permission, while releasing claims well beyond those presented in the case.”
And so an amended class action complaint was filed in 2011, only to be dismissed in 2013 by a U.S. District Court judge [PDF].
In dismissing the case, that judge declared that Google Books passes the 4-point sniff test for fair use.
First, the program is transformative and non-commercial. It “digitizes books and transforms
expressive text into a comprehensive word index that helps readers, scholars, researchers, and others find books.” It also “does not supersede or supplant books because it is not a tool to be used to read books.”
Second, the scanned texts have all been previously published and made available to the public. Unpublished works present a higher bar for fair use considerations.
The third factor in the fair use test involves how much of the original text is made available. While the judge acknowledged that Google puts limits on what can be seen, this factor “weighs slightly against a finding of fair use.”
Finally, there’s the consideration of what sort of impact Google Books might have on the market value for the scanned texts.
The Guild had argued that the Google snippets could serve as a “market replacement” for the scanned books, and that freeloaders could use multiple search terms to eventually obtain all the pages of a book for free.
But the judge found that these arguments didn’t make sense.
“Google does not sell its scans, and the scans do not replace the books,” reads the dismissal. “While partner libraries have the ability to download a scan of a book from their collections, they owned the books already — they provided the original book to Google to scan. Nor is it likely that someone would take the time and energy to input countless searches to try and get enough snippets to comprise an entire book.”
The judge contended that in order for someone to piece together enough snippets to obtain a full book, that person would already need to have a copy of the book in their possession.
The plaintiffs appealed the dismissal to the U.S. Second Circuit, located in New York City, the heart of the U.S. book publishing industry.
In this morning’s appeals court opinion [PDF], the panel upholds the lower court’s ruling and explains further why it believes that Google Books constitutes a fair use of the scanned texts.
“The purpose of Google’s copying of the original copyrighted books is to make available significant information about those books, permitting a searcher to identify those that contain a word or term of interest, as well as those that do not include reference to it,” explains the court. “In addition… Google allows readers to learn the frequency of usage of selected words in the aggregate corpus of published books in different historical periods.”
This satisfies, in the panel’s view, the “transformative” portion of the fair use test.
Additionally, the court defended the importance of Google’s snippets, as they provide context for the search results.
Without snippets, users only know “whether and how often the searched term appears in the book,” according to the ruling. Merely knowing a term exists in a book is not sufficient for evaluating that book’s value as a resource.
“Google’s division of the page into tiny snippets is designed to show the searcher just enough context surrounding the searched term to help her evaluate whether the book falls within the scope of her interest (without revealing so much as to threaten the author’s copyright interests),” explains the court.
With regard to the issue of how much text is included in those snippets — a matter that the lower court acknowledged was not in Google’s favor — the appeals court found that, “Complete unchanged copying has repeatedly been found justified as fair use when the copying was reasonably appropriate to achieve the copier’s transformative purpose and was done in such a manner that it did not offer a competing substitute for the original.”
The court notes that Google does make an unauthorized digital copy of the entire book, but it does not reveal that full copy to the public.
“The copy is made to enable the search functions to reveal limited, important information about the books,” explains the opinion, which states that the current format of Google Books search results do not “reveal matter that offers the marketplace a significantly competing substitute for the copyrighted work.”
The appeals court acknowledged that the “snippet function can cause some loss of sales,” and that “There are surely instances in which a searcher’s need for access to a text will be satisfied by the snippet view, resulting in either the loss of a sale to that searcher, or reduction of demand on libraries for that title, which might have resulted in libraries purchasing additional copies.”
But, countered the panel, the potential — or even certain — loss of some sales “does not suffice to make the copy an effectively competing substitute” that would negate the fair use argument. “There must be a meaningful or significant effect ‘upon the potential market for or value of the copyrighted work.'”
In fact, according to the court, many of the instances in which a search result might satisfy someone’s interest in buying a book or borrowing it from a library involve searches for historical fact.
It gives the example of someone looking to confirm that Franklin D. Roosevelt had polio. A search for “roosevelt polio” might turn up a book confirming the president’s illness and when he contracted the virus. The researcher’s needs are fulfilled without buying the book or borrowing it from a library, but what was gleaned from the search were mere facts that aren’t protected by copyright.
“[C]opyright does not extend to the facts communicated,” in a book, explains the panel. “It protects only the author’s manner of expression.”
Google could provide those facts, citing the Roosevelt book, without the author’s permission.
Aside from setting pro-fair use precedent, another important aspect of today’s ruling — which could still be appealed to the U.S. Supreme Court — is that it means Google and the Authors Guild will not try to enter into any sort of settlement like the one rejected by the court in 2011.
That sort of arrangement would have had the effect of making Google the only online repository for this sort of research. No other competitor would have been able to amass such a collection of scanned titles for a relatively little amount of money given the number of books involved.
While today’s ruling doesn’t add any new competitors to the book-scanning field, it clarifies that it’s perfectly legal for others to launch their own scanning and search programs.
Want more consumer news? Visit our parent organization, Consumer Reports, for the latest on scams, recalls, and other consumer issues.